Like most people, I send and receive a lot of documents over email, and the vast majority of those are in PDF format. Over the last few months, I’ve been playing with the idea of moving all these documents into a single location and building an application to automatically index them. This would not only make it easier to find a specific one quickly, but also simplify backing things ups.
Fast forward to last week, and I was reading about some of the Watson services in IBM Bluemix. It occurred to me that it would be fairly easy to combine the Watson Document Conversion service with the AlchemyAPI Keyword Extraction service to automatically turn PDFs into text and then extract keywords from them. I could store the keywords in a database and wrap a search interface around it to create a fairly neat little PDF storage/search application.
As it turned out, it worked exactly as I’d thought it would. A few hours of coding and I had the skeleton of a working application. A few more hours to hook it up with a couple of data stores (MongoDB for the keywords, a Swift object store for the actual PDFs) and add a pretty GUI, and my application was live on Bluemix.
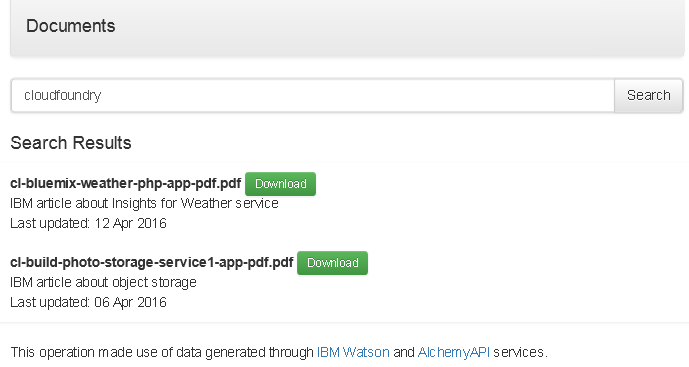
The final version lets users select and upload PDF documents from their computer. As each document is uploaded, it is automatically and intelligently scanned for keywords and those keywords are extracted and stored in a database. Users can later search by keyword to quickly identify and download documents relevant to their needs. Needless to say, it’s all mobile-optimized, so you can get to your documents from both your smartphone and your desktop computer.
Here’s an example of what it looks like in action:
Try the prototype out, or fork the code on Github. If you’re interested in finding out more, read my developerWorks article, which walks you through all the technical details.